Deep Learning Implementation
Where research begins: Expert guidance on topic selection.
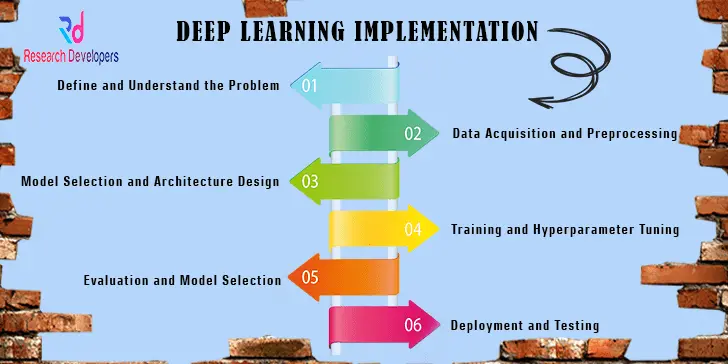
Deep Learning Implementation
Deep learning is an AI and ML technique that attempts to replicate the way people learn new things. You can train deep learning models to identify patterns in images, text, and audio, among other types of data, and to carry out classification tasks. Image description and audio file transcription are two examples of the kinds of jobs that would typically require human intelligence and can be automated with its help.
Data science, which includes statistical analysis and forecasting, relies heavily on deep learning. Those data scientists whose jobs it is to gather, analyse, and make sense of massive datasets will find deep learning to be an invaluable tool.
Neural networks built from numerous layers of software nodes collaborate in deep learning, much like the millions of interconnected neurons in a human brain. To train their models, deep learning systems use neural network designs and massive amounts of labelled data.
Deep Learning is defined as a Machine Learning technique that is used to process multiple inputs at parallel. It is designing in such a way for minimizing the processing time. It can handle different scalability in the system. The process of training in this type of methods is able to improve accuracy in testing, since it learns better from the training. The methods in deep learning are able tpo process larger sized datasets. Hereby few of the deep learning techniques are listed.
Deep Learning Methods
• Deep Belief Network
• Deep Boltzman Machine
• Recurrent Neural Network
• Generative Adversarial Network
• Self Organizing Maps
• Gated Recurrent Neural Network
The functioning of deep learning
Computer programmes employing deep learning undergo a similar process to that of a toddler acquiring the ability to recognise a dog, for instance. Deep learning programmes consist of numerous layers of interconnected nodes, where each layer increases in complexity and improves predictions and classifications by building upon the previous one. The process of deep learning involves the application of nonlinear transformations to the input data, which is then utilised to generate a statistical model as the output. The process of iteration persists until the output has attained a satisfactory degree of precision. The moniker “deep” was inspired by the number of processing layers that data must traverse.
In conventional ML, the learning process is supervised, necessitating the programmer to provide highly precise instructions to the computer regarding the specific criteria it should consider in order to determine if an image contains a dog or not. Feature extraction is a time-consuming procedure, and the computer’s success rate relies solely on the programmer’s proficiency in precisely defining a collection of features for dogs. Deep learning offers the benefit of autonomously constructing the feature set without the need for supervision.
At first, the computer programme could be given training data, which consists of photos that have been labelled as either dog or not dog by a human using metatags. The software builds a prediction model using the data obtained from the training dataset and uses it to develop a collection of canine characteristics. This is an example of a situation where the first computer model could assume that everything with four legs and a tail in a picture is a dog.
Naturally, the programme lacks awareness of the descriptors “four legs” or “tail.” The process involves the identification of pixel patterns within the digital data. As the iteration progresses, the predictive model exhibits an increase in complexity and accuracy.
In contrast to an infant, who needs weeks or even months to understand what a dog is, a computer programme that uses deep learning methods can analyse millions of photos in just a few minutes after being given a training set. This computer programme can accurately detect the presence of dogs in these photos.
In order to get a satisfactory degree of precision, deep learning algorithms necessitate access to vast quantities of training data and computational capabilities, both of which were not readily accessible to developers until the advent of cloud computing and big data. Due to its ability to generate intricate statistical models straight from its iterative output, deep learning programming possesses the capability to construct precise prediction models from substantial volumes of unlabeled and unstructured data.
Deep learning techniques
Multiple techniques can be employed to construct robust deep learning models. Some of the approaches employed in this context encompass training from scratch, learning rate decay, dropout, and transfer learning.
learning rate degradation
The learning rate is a hyperparameter which governs the adjustment of the model’s weights in response to changes in the estimated error. It serves as a defining factor for the system and establishes the conditions under which it operates before the learning process. A poor weight set may be acquired or unstable procedures for training may result from excessive learning rates. Low learning rates might lead to a training process that takes a long time and can get stagnant.
A process called learning rate decay—also called adaptive learning rate or learning rate annealing —involves modifying the learning rate to maximise efficiency and decrease training time. The most straightforward and prevalent adjustments to the learning rate during training involve employing methods to gradually decrease the learning rate.
Transfer learning
The aforementioned procedure entails refining a model that has been previously trained, necessitating an interface to the internal workings of an existing network. Initially, users input novel data into the preexisting network, which encompasses previously unidentified categorizations. After making modifications to the network, it becomes possible to execute new jobs with enhanced categorization capabilities. This approach offers the benefit of necessitating far less data compared to alternative methods, hence diminishing the computational time to hrs or minutes.
Initial training from scratch
This approach necessitates a developer to gather a substantial, annotated dataset and establish a network structure capable of acquiring knowledge about the characteristics and model. This approach works wonderfully for newly-developed apps or those with a wide variety of output types. Training with this method could take days—if not weeks—because of the massive amounts of data it requires. Consequently, it is not as common as other approaches.
Neural networks based on deep learning
A complex machine learning technique called an artificial neural network (ANN) forms the backbone of most deep learning models. Sometimes, people will refer to deep learning as deep neural learning or just DDN. DDNs are composed of three layers: input, hidden, and output. Input nodes serve as a layer for the purpose of storing input data. It is necessary to modify the number of output layers and nodes per output. For instance, binary outputs necessitate only two nodes, whereas outputs containing additional data necessitate a greater number of nodes. The concealed layers encompass a series of layers that undertake the processing and transmission of data to subsequent layers inside the neural network.
Neural networks are available in various forms, which include:
1. Convolutional neural networks.
2. Recurrent neural networks
3. Artificial neural networks (ANNs) and feed.
4. Neural networks are being advanced
Different types of neural networks offer distinct advantages for particular applications. Nevertheless, these models operate in a relatively same manner, wherein they input data and allow the model to autonomously determine whether it has accurately interpreted or made a conclusion regarding a specific data element.
Neural networks employ a heuristic approach, necessitating substantial quantities of data for training purposes. The surge in popularity of neural networks can be attributed to the widespread adoption of big data analytics by organisations, which led to the accumulation of substantial volumes of data. Due to the initial iterations of the model, which rely on educated guesses about the image’s contents or portions of speech, it is necessary to label the data used during the training stage. This allows the model to assess the accuracy of its estimates. Unstructured data is less beneficial. The analysis of unstructured data by a deep learning model is contingent upon its training and attainment of a satisfactory degree of accuracy. Nevertheless, it is essential to specify that deep learning models are unable to undergo training on unstructured data.
Our technical team is experienced in working and has enough knowledge to innovate a research using Deep Learning. We offer all type of service including implementing and simulation. You can discuss with our technical experts and know more for understanding and work ahead in your project.
Dropout
This method uses a random removal of units and their connections during training to solve the overfitting problem in neural networks with many parameters. Document classification, voice recognition, and computational biology are just a few examples of supervised learning domains where research has shown that the dropout strategy can improve NN’s performance.
Other Services
- PHD & POST DOC Admission counselling
- Topic Section
- Review Paper Writing
- Systematic Literature Review (SLR)
- Research Paper Writing
- Synopsis Writing/Pre thesis writing
- Thesis Writing
- Data Analysis
- Questionnaire Preparation
- Developing Research Framework
- Methodology Development
- MATLAB Implementation
- Matlab Simulation
- Python Implementation
- Machine Learning Implementation
- Deep Learning Implementation
- VHDL Implementation
- Hadoop
- NS2 Implementation
- NS3 Implementation
- ArcGis Mapping & Analysis
- Spss Data Analysis
- Stata Data Analysis
- Amos Analysis
- R Programming
- E-Views Data Analysis
- Minitab Data Analysis
- Software Testing
- Ansys Implementation
